
티스토리 뷰
스파크 스트리밍 + 카프카, Spark streaming + Kafka
스파크 스트리밍 + 카프카, Spark streaming + Kafka
요즘에 구상하고 있는 연구의 모델이, 각 서버로 부터 실시간 로그를 받아서 값을 분석하여 최적화하는거라 스파크 스트리밍을 보고있다. 스파크 스트리밍을 선택하자라는 결론에 도달했을때, 입력 소스는 어떻게..
alphahackerhan.tistory.com

| 카프카(Kafka)란?
아파치 카프카(Apache Kafka)는 분산 스트리밍 플랫폼이며 데이터 파이프 라인을 만들 때 주로 사용되는 오픈소스 솔루션입니다. 카프카는 대용량의 실시간 로그처리에 특화되어 있는 솔루션이며 데이터를 유실없이 안전하게 전달하는 것이 주목적인 메세지 시스템에서 Fault-Tolerant한 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리할 수 있습니다.
카프카는 현재 2.x 버전까지 나와있고 초기에 Producer, Consumer 기능에서 0.10.x 버전에서부터 Connectors와 Stream Processors가 추가되었습니다.
이 포스팅에서는 Producer, Consumer에 대해서만 다룰 것이며 카프카가 어떤 아키텍처로 구성되어 있고 어떻게 동작하는 지 간략하게 설명하도록 하겠습니다.
| 카프카의 특징(Kafka Features)
■ Publisher Subscriber 모델 : Publisher Subscriber 모델은 데이터 큐를 중간에 두고 서로 간 독립적으로 데이터를 생산하고 소비합니다. 이런 느슨한 결합을 통해 Publisher나 Subscriber가 죽을 시, 서로 간에 의존성이 없으므로 안정적으로 데이터를 처리할 수 있습니다. 또한 설정 역시 간단하게 할 수 있다는 장점이 있습니다.
■ 고가용성(High availability) 및 확장성(Scalability) : 카프카는 클러스터로서 작동합니다. 클러스터로서 작동하므로 Fault-tolerant 한 고가용성 서비스를 제공할 수 있고 분산 처리를 통해 빠른 데이터 처리를 가능하게 합니다. 또한 서버를 수평적으로 늘려 안정성 및 성능을 향상시키는 Scale-out이 가능합니다.
■ 디스크 순차 저장 및 처리(Sequential Store and Process in Disk) : 메세지를 메모리 큐에 적재하는 기존 메세지 시스템과 다르게 카프카는 메세지를 디스크에 순차적으로 저장합니다. 이로서 얻는 이점은 두 가지입니다.
1. 서버에 장애가 나도 메세지가 디스크에 저장되어 있으므로 유실걱정이 없습니다.
2. 디스크가 순차적으로 저장되어 있으므로 디스크 I/O가 줄어들어 성능이 빨라집니다.
■분산 처리(Distributed Processing) : 카프카는 파티션(Partition)이란 개념을 도입하여 여러개의 파티션을 서버들에 분산시켜 나누어 처리할 수 있습니다. 이로서 메세지를 상황에 맞추어 빠르게 처리할 수 있습니다.
| 카프카 아키텍처 및 구성(Kafka Architecture and Components)
카프카 공식 문서에 나온 카프카를 나타내는 간단한 아키텍처입니다. (0.9.x 기준)
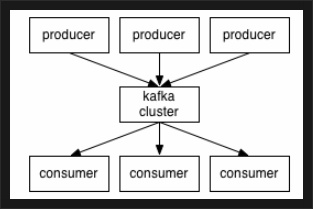
<출처: https://kafka.apache.org/090/documentation.html>
카프카 클러스터를 중심으로 프로듀서와 컨슈머가 데이터를 push하고 pull하는 구조입니다. Producer, Consumer는 각기 다른 프로세스에서 비동기로 동작하고 있죠. 이 아키텍처를 좀 더 자세히 표현하면 다음과 같습니다.
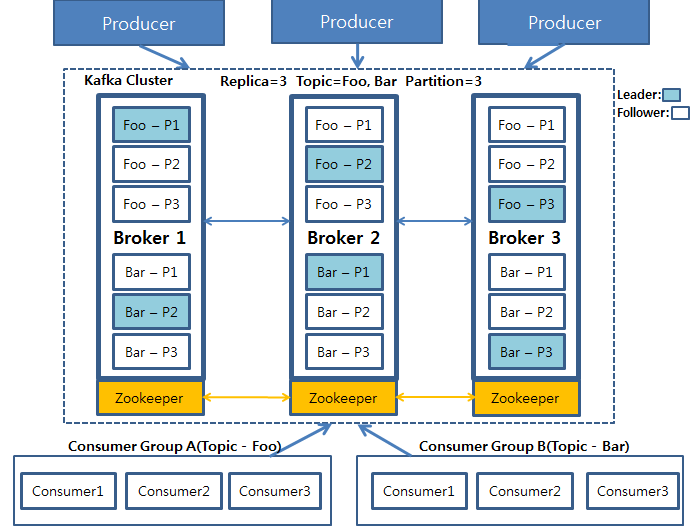
위 그림을 설명하기 이전에 아키텍처를 구성하고 있는 구성요소들 먼저 설명하도록 하겠습니다.
■ 프로듀서(Producer) : 데이터를 발생시키고 카프카 클러스터(Kafka Cluster)에 적재하는 프로세스입니다.
■ 카프카 클러스터(Kafka Cluster) : 카프카 서버로 이루어진 클러스터를 말합니다. 카프카 클러스터를 이루는 각 요소는 다음과 같습니다.
- 브로커(Broker) : 카프카 서버를 말합니다.
- 주키퍼(Zookeeper) : 주키퍼(Zookeeper)는 분산 코디네이션 시스템입니다. 카프카 브로커를 하나의 클러스터로 코디네이팅하는 역할을 하며 나중에 이야기할 카프카 클러스터의 리더(Leader)를 발탁하는 방식도 주키퍼가 제공하는 기능을 이용합니다.
- 토픽(Topic) : 카프카 클러스터에 데이터를 관리할 시 그 기준이 되는 개념입니다. 토픽은 카프카 클러스터에서 여러개 만들 수 있으며 하나의 토픽은 1개 이상의 파티션(Partition)으로 구성되어 있습니다. 어떤 데이터를 관리하는 하나의 그룹이라 생각하시면 됩니다.
- 파티션(Partition) : 각 토픽 당 데이터를 분산 처리하는 단위입니다. 카프카에서는 토픽 안에 파티션을 나누어 그 수대로 데이터를 분산처리합니다. 카프카 옵션에서 지정한 replica의 수만큼 파티션이 각 서버들에게 복제됩니다.
- 리더, 팔로워(Leader, Follower) : 카프카에서는 각 파티션당 복제된 파티션 중에서 하나의 리더가 선출됩니다. 이 리더는 모든 읽기, 쓰기 연산을 담당하게 됩니다. 리더를 제외한 나머지는 팔로워가 되고 이 팔로워들은 단순히 리더의 데이터를 복사하는 역할만 하게 됩니다.
■컨슈머그룹(Consumer Group) : 컨슈머의 집합을 구성하는 단위입니다. 카프카에서는 컨슈머 그룹으로서 데이터를 처리하며 컨슈머 그룹 안의 컨슈머 수만큼 파티션의 데이터를 분산처리하게 됩니다.
위 그림에서는 Producer가 데이터를 카프카에 적재하고 있으며 그 저장된 데이터를 Consumer Group A와 B가 각각 자신이 처리해야될 Topic Foo와 Bar를 가져오는 그림입니다.
Foo와 Bar은 각각 3개의 파티션으로 나뉘어져 있으며 이 각각의 파티션들은 3개의 복제본으로 복제됩니다. 3개의 복제본 중에는 하나의 리더가 선출되게 되고(하늘색으로 칠해진 파티션) 이 리더가 모든 데이터의 읽기, 쓰기 연산을 담당하게 됩니다.
중요한 것은 이 파티션들은 운영 도중 그 수를 늘릴 수 있지만 절대 줄일 수 없습니다. 이 때문에 파티션을 늘리는 것은 신중하게 고려해서 결정해야될 문제가 됩니다.
카프카 클러스터에서 데이터를 가져오게 될 때는 컨슈머 그룹(Consumer Group)단위로 가져오게 됩니다. 이 컨슈머 그룹은 자신이 가져와야하는 토픽 안의 파티션의 데이터를 Pull하게 되고 각각 컨슈머 그룹안의 컨슈머들이 파티션이 나뉘어져 있는 만큼 데이터를 처리하게 됩니다.
| 카프카 파티션 읽기, 쓰기(Kafka Partition, Read, Write)

카프카에서의 쓰기, 읽기 연산은 카프카 클러스터 내의 리더 파티션들에게만 적용됩니다. 하늘색으로 칠해진 각 파티션들은 리더 파티션이며 이 파티션들에게 프로듀서가 쓰기 연산을 진행합니다. 그리고 리더 파티션에 쓰기가 진행되고 난 후 업데이트된 데이터는 각 파티션들의 복제본들에게로 복사됩니다.
아래는 프로듀서가 어떻게 각 파티션들에 Write 연산을 진행하는 지 설명하는 그림입니다.
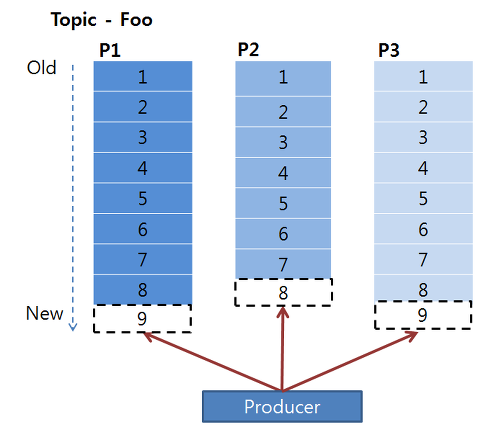
위에서 언급했듯 카프카는 데이터를 순차적으로 디스크에 저장합니다. 따라서 프로듀서는 순차적으로 저장된 데이터 뒤에 붙이는 append 형식으로 write 연산을 진행하게 됩니다. 이 때 파티션들은 각각의 데이터들의 순차적인 집합인 오프셋(offset)으로 구성되어 있습니다.

컨슈머그룹의 각 컨슈머들은 파티션의 오프셋을 기준으로 데이터를 순차적으로 처리하게 됩니다. (먼저 들어온 순서부터) 중요한 것은, 컨슈머들은 컨슈머 그룹으로 나뉘어서 데이터를 분산 처리하게 되고 같은 컨슈머 그룹 내에 있는 컨슈머끼리 같은 파티션의 데이터를 처리할 수 없습니다.
파티션에 저장되어 있는 데이터들은 순차적으로 데이터가 저장되어 있으며 이 데이터들은 설정값에 따라 데이터를 디스크에 보관하게 됩니다. (2.x 기준 default 7일)
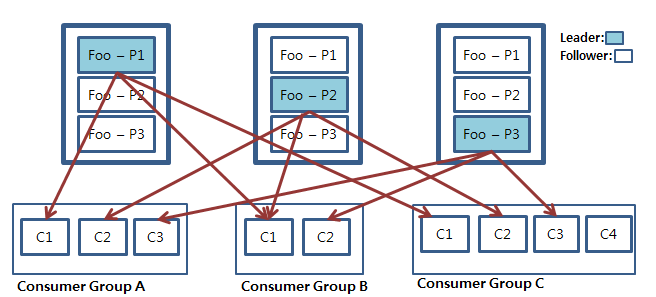
위 그림은 컨슈머 그룹단위로 그룹 내 컨슈머들이 각각의 파티션의 데이터를 처리하는 모습을 나타낸 것입니다.
만일 컨슈머와 파티션의 개수가 같다면 컨슈머는 각 파티션을 1:1로 맡게 됩니다. 만일 컨슈머 그룹 안의 컨슈머의 개수가 파티션의 개수보다 적을 경우 컨슈머 중 하나가 남는 파티션의 데이터를 처리하게 됩니다. 눈여겨 볼 것은 만일 컨슈머의 개수가 파티션의 개수보다 많을 경우 남는 컨슈머는 파티션이 개수가 많아질 때까지 대기하게 됩니다.
출처: https://engkimbs.tistory.com/691 [새로비]
그렇다면, 아파치 카프카(Apache Kafka)는 무엇일까.
카프카는 대용량 실시간 처리를 위해 사용하는 메시징 시스템이며, Pub-Sub 구조를 이용한다.
요즘 잘나간다는 글로벌 서비스들(LinkedIn, Twitter, Netflix, Tumblr, Foursquare 등)은 대용량 데이터를 처리하기 위해 카프카를 쓰고 있다.
카프카에 더 자세한 이야기는 다른 포스팅을 통해 따로 다루도록 하고,
이번 포스팅의 주 목적인 스파크 스트리밍 + 카프카에 대해서 알아보자.
카프카에 대한 내장 지원 모듈을 쓰면 쉽게 많은 토픽에 대한 메세지를 처리할 수 있다.
이를 사용하기 위해서는 프로젝트에 (Maven을 쓸 경우엔 Pom.xml에) spark-streaming-kafka_2.10 아티팩트 (artifact)를 추가해야한다.
물론 아티팩트나 버전에 기술되는 값은 상황에 맞게 적절하게 기술되어져야 한다. 본인이 사용하고 있는 스파크 버전, 스칼라 버전, 카프카 버전 등을 잘 살펴봐야하며, 서로 호환이 되는 것인지도 확인해야한다.
또한, 자신이 작성한 메소드나 객체가 해당 버전의 디펜던시를 통해 import 시킬 수 있는 것인지도 확인이 되어야, 실제로 코딩할 때 예상치 못한 부분에서 에러가 발생하여, 어리둥절해 지는 순간을 최소화할 수 있다.
참고로 이런 부분은 스파크 공식 홈페이지를 통해 가장 간단하게 해결할 수 있다. 그곳의 도큐먼트에 아주 친절하게 잘 설명되어있다. (어설프게 구글링하다가 디펜던시도 꼬이고 코드도 꼬이는 불상사를 막자..)
어쨌든 디펜던시들이 정상적으로 잘 적용됐을때, 제공되는 KafkaUtils 객체는 StreamingContext에서 동작하며, 카프카 메세지의 DStream을 생성한다.
카프카 스트림은 여러 토픽에 대한 메세지를 받아 볼 수 있으므로, 여기서 만들어진 DStream은 토픽과 메세지의 쌍들로 구성된다.
스파크 스트리밍과 카프카를 연결하는 방법에는 두가지 접근법있다.
- Recevier-based Approah
- Direct Approach (No Receviers)
스파크는 데이터를 주고 받는 과정에 있어서, 더 나은 수준의 fault-tolerance와 신뢰 수준을 보장하기 위해, Spark 1.2에서 Write Ahead Logs (WAL)를 선보였었다. 이를 통해 스파크는 신뢰가 높은 입력 소스(Flume, Kafka, Kinesis)로 부터 들어온 것들 뿐만 아니라, 평범하고 오래된 소켓으로 부터 들어온 신뢰도 떨어지는 것들까지, 오류로 인한 데이터 손실이 없도록 (최소화하도록) 보장했다.
특히, 카프카와 같은 입력 소스는 데이터 스트림의 임의의 위치에 replaying을 허용한다. 이 경우, 그 입력 소스는 스파크 스트리밍에게 데이터 스트림 소비에 관한 더 많은 제어권을 부여하기 때문에, 더 강력한 fault-tolerance의 의미를 가진다. 이것이 Recevier-based Approach다.
Spark 1.3에서 Direct API라는 개념을 선보였는데, 이를 통해 WAL를 사용하지 않고도 한번만에 처리할 수 있도록 했다. 이것이 Direct Approach (No Receivers)이고 exactly-once 방식이라고도 한다.
Approach 1: Receiver-based Approach
이 방식이 돌아가는 방식은 아래와 같다.
- 데이터는 카프카 리시버 (Kafka Receiver)로 부터 지속적으로 받아진다.
- 이때, 리시버는 스파크 워커 노드에 있으며, 카프카의 High-Level Consumer API를 사용한다
- 들어온 데이터는 스파크 워커 노드의 메모리와 WAL에 저장된다 (또한, HDFS에도 복제될 것이다). 그리고 카프카 리시버는 Zookeeper에 카프카의 오프셋을 업데이트한다.
- 들어온 데이터와 그것의 WAL 위치에 대한 정보 역시 저장된다. 만약에 오류가 발생하면, 그 정보를 이용해서 다시 데이터를 읽고 처리할 수 있다.
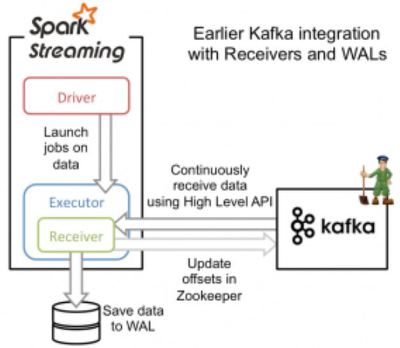
이렇게 하면, 카프카로 부터 들어오는 데이터가 유실되거나 손실되지 않을 거라는 보장을 할수는 있지만, 오류로 인해 어떤 데이터 레코드가 한번 이상 처리될 수 있는 가능성이 있다. 다시말해 이것은 at-least-once 방식이다.
가령, 어떤 데이터가 잘들어와서 WAL에 까지 잘 저장됐는데, 주키퍼에 업데이트를 하기전에 오류가 발생한다면, 시스템 간의 일관성이 깨지게 된다. 왜냐면, 스파크 스트리밍 입장에서는 데이터를 정상적으로 잘 받아서, 잘 저장시켰지만. 카프카 입장에서는 주키퍼의 카프카 오프셋이 업데이트 되질 않았으니 데이터가 정상적으로 보내지지 않았다고 생각할 것이기 때문이다. 그래서 카프카는 이미 잘 저장되어 있는 데이터를 다시 보내게 된다.
이렇게 움직이는 정보(혹은 이미 보내진 정보)를 가지고, 시스템 간의 일관성을 맞추려니 잘 안되는 것이다. 이러한 문제를 방지하기 위해, 이런 일관성을 관리하고 유지하는 엔티티를 하나로 만들어주자는 생각에서 Direct Approach가 나오게 됐다.
Approach 2: Direct Approach (No Receivers)
이 방식에서는 데이터 오프셋에 대한 관리를 오직 스파크 스트리밍에서만 하도록 했다. 그리고 오류가 발생해서 데이터를 다시 보내야하는 경우(replaying data)엔 카프카의 Simple Consumer API를 사용하여 해결할 수 있도록 했다.
이것은 기존 리시버 + WAL 방식과는 완전히 다른 방식이다. 리시버를 통해 연속적인 데이터를 받고, 그것을 WAL에 저장하는 방식 대신, 간단하게, 모든 batch interval이 시작되는 순간마다 소비해야하는 (Consume) 데이터의 오프셋의 범위를 결정하게 했다. 그 후, 각 batch의 job이 실행될 때, 해당 범위의 데이터를 카프카로 부터 불러온다 (HDFS에서 파일을 읽는 방식과 비슷하다). 물론, 이 오프셋은 체크포인트를 이용해서 안정적으로 저장되며 오류가 발생했을때 그것을 이용해서 복구할 수 있다.
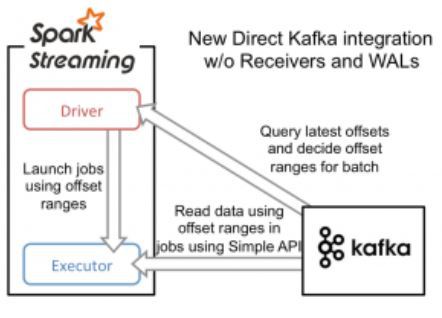
이러한 방식으로 스파크 스트리밍은 Direct Approach를 이용해, 카프카의 데이터들을 한번에, 효율적으로 받으면서도, 리시버와 WAL가 필요없게 만들었다.
- Total
- Today
- Yesterday
- 코로나19
- directory copy 후 startup 에러
- 튜닝
- 테라폼
- 커널
- 쿠버네티스
- 여러서버 컨트롤
- 버쳐박스
- 오라클
- [오라클 튜닝] instance 튜닝2
- 앤시블
- 설치하기(HP-UX)
- ubuntu
- 스토리지 클레스
- ORACLE 트러블 슈팅(성능 고도화 원리와 해법!)
- 5.4.0.1072
- 오라클 트러블 슈팅(성능 고도화 원리와 해법!)
- K8s
- 오라클 홈디렉토리 copy 후 startup 에러
- [오라클 튜닝] sql 튜닝
- startup 에러
- 키알리
- pod 상태
- Oracle
- 우분투
- MSA
- 트리이스
- CVE 취약점 점검
- 오라클 인스턴트클라이언트(InstantClient) 설치하기(HP-UX)
- (InstantClient) 설치하기(HP-UX)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |