
티스토리 뷰
Apache Cassandra에서 Amazon DynamoDB로 데이터 마이그레이션
AWS SCT 데이터 추출 에이전트를 사용하여 Apache Cassandra의 데이터를 추출하고 Amazon DynamoDB로 마이그레이션할 수 있습니다. 이 에이전트는 Amazon EC2 인스턴스에서 실행되어 Cassandra의 데이터를 추출하고 로컬 파일 시스템에 쓴 후 Amazon S3 버킷에 업로드합니다. 그런 다음 AWS SCT를 사용하여 DynamoDB에 데이터를 복사할 수 있습니다.
Amazon DynamoDB는 NoSQL 데이터베이스 서비스입니다. DynamoDB에 데이터를 저장하려면 데이터베이스 테이블을 만든 후 이 테이블에 데이터를 업로드합니다. Cassandra용 AWS SCT 추출 에이전트는 해당 Cassandra 대상에 맞는 DynamoDB 테이블을 만든 후 이러한 DynamoDB 테이블을 Cassandra의 데이터로 채우는 프로세스를 자동으로 수행합니다.
데이터 추출 프로세스는 Cassandra 클러스터에 상당한 오버헤드를 줄 수 있습니다. 따라서 Cassandra의 프로덕션 데이터에 대해 추출 에이전트를 직접 실행하지 마십시오. 프로덕션 애플리케이션을 방해하지 않기 위해 AWS SCT는 복제 데이터센터—를 만들어 줍니다. 이것은 DynamoDB로 마이그레이션하려는 Cassandra 데이터의 독립적인 사본입니다. 그런 다음 에이전트는 복제본에서 데이터를 읽어 AWS SCT가 프로덕션 애플리케이션에 영향을 주지 않고 사용할 수 있게 해줍니다.
데이터 추출 에이전트를 실행하면 복제 데이터 센터의 데이터를 읽어서 Amazon S3 버킷에 씁니다. 그런 다음 AWS SCT는 Amazon S3에서 데이터를 읽어서 Amazon DynamoDB에 씁니다.
다음 다이어그램은 지원되는 시나리오를 보여 줍니다.

AWS DMS는 Apache Cassandra 버전 2.0과 3.0을 소스로 지원하고 Amazon DynamoDB를 대상으로 지원합니다.
Cassandra를 처음 사용하는 경우 다음과 같은 중요 개념을 이해해야 합니다.
-
노드는 Cassandra 소프트웨어를 실행하는 하나의 컴퓨터(실제 컴퓨터 또는 가상 컴퓨터)입니다.
-
서버는 최대 256개의 노드로 구성된 논리적 엔터티입니다.
-
랙은 한 개 이상의 서버를 나타냅니다.
-
데이터 센터는 랙 모음입니다.
-
클러스터는 데이터 센터의 모음입니다.
자세한 내용은 Apache Cassandra에 대한 Wikipedia 페이지를 참조하십시오.
다음 단원의 정보를 사용하여 Apache Cassandra의 데이터를 Amazon DynamoDB로 마이그레이션하는 방법을 알아봅니다.
항목
Cassandra에서 DynamoDB 마이그레이션하기 위한 사전 조건
시작하기 전에 이 단원에서 설명한 대로 몇 가지 마이그레이션 사전 작업을 수행해야 합니다.
Amazon S3 설정
AWS SCT 데이터 추출 에이전트를 실행하면 에이전트가 복제 데이터센터의 데이터를 읽은 후 Amazon S3 버킷에 씁니다. 계속하려면 AWS 계정 및 Amazon S3 버킷에 연결하기 위한 자격 증명을 제공해야 합니다. 자격 증명 및 버킷 정보를 전역 애플리케이션 설정 내 프로필에 저장하고 프로필을 AWS SCT 프로젝트와 연결합니다. 필요한 경우, [Global Settings]를 선택하여 새 프로필을 생성합니다. 자세한 내용은 AWS Schema Conversion Tool에서 AWS 서비스 프로파일 사용 단원을 참조하십시오.
복제 데이터센터를 위한 Amazon EC2 인스턴스
마이그레이션 프로세스의 일부로, 기존 Cassandra 데이터 센터의 복제본을 만들어야 합니다. 이 복제본은 미리 할당한 Amazon EC2 인스턴스에서 실행됩니다. 이 인스턴스는 기존 Cassandra 데이터 센터와 독립적으로 복제 데이터 센터를 호스팅하기 위해 독립적인 Cassandra 설치를 실행합니다.
새로운 Amazon EC2 인스턴스는 다음 요구 사항을 충족해야 합니다.
-
운영 체제: Ubuntu 또는 CentOS
-
Java JDK 8이 설치되어 있어야 합니다. (다른 버전은 지원되지 않습니다.)
새 인스턴스를 시작하려면 https://console.aws.amazon.com/ec2/에서 Amazon EC2 Management Console로 이동합니다.
보안 설정
AWS SCT는 SSL(Secure Sockets Layer)을 사용하여 데이터 추출 에이전트와 통신합니다. SSL을 활성화하려면 트러스트 스토어와 키 스토어를 설정합니다.
-
AWS SCT를 시작합니다.
-
설정 메뉴에서 글로벌 설정을 선택합니다.
-
다음과 같이 보안 탭을 선택합니다.
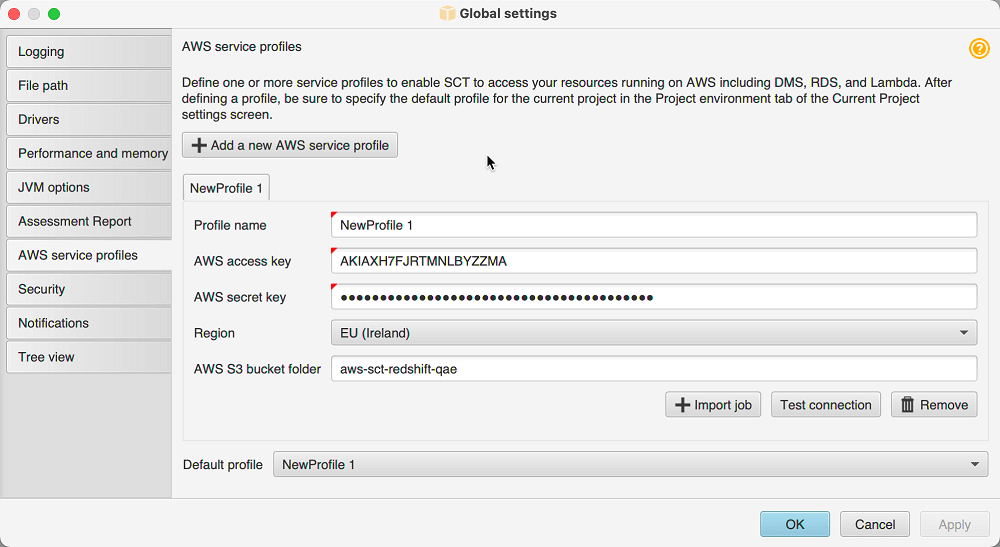
-
[Generate Trust and Key Store]를 선택하거나 [Select existing Trust and Key Store]를 선택합니다.
[Generate Trust and Key Store]를 선택한 경우, 트러스트 및 키 스토어의 이름과 암호, 그리고 생성된 파일이 저장될 위치의 경로를 지정합니다. 이들 파일은 이후 단계에서 사용합니다.
[Select existing Trust and Key Store]를 선택한 경우, 트러스트 및 키 스토어의 암호와 파일 이름을 지정합니다. 이들 파일은 이후 단계에서 사용합니다.
-
트러스트 스토어와 키 스토어를 지정한 후 [OK]를 선택하여 [Global Settings] 대화 상자를 닫습니다.
새 AWS SCT 프로젝트 만들기
Cassandra에서 DynamoDB 마이그레이션하기 위한 사전 조건의 절차를 수행했으면 이제 새로운 AWS SCT 프로젝트를 만들 수 있습니다. 다음 절차를 따르십시오.
-
파일 메뉴에서 새 프로젝트를 선택합니다.

다음 정보를 입력합니다.
파라미터... 수행할 작업 [프로젝트 이름]
컴퓨터에서 로컬로 저장되는 프로젝트의 이름을 입력합니다.
위치
로컬 프로젝트 파일의 위치를 입력합니다.
NoSQL 데이터베이스
NoSQL 데이터베이스를 선택합니다.
소스 데이터베이스 엔진
Cassandra를 선택합니다.
대상 데이터베이스 엔진
Amazon DynamoDB를 선택합니다.
[OK]를 선택하여 AWS SCT 프로젝트를 생성합니다.
-
메뉴 모음에서 Cassandra에 연결을 선택합니다.

다음 정보를 입력합니다.
파라미터... 수행할 작업 [Server name]
Cassandra 클러스터의 호스트 이름 또는 IP 주소를 입력합니다.
[Server port]
Cassandra가 연결 요청을 수신하는 포트 번호를 입력합니다. 예: 9042
사용자 이름
Cassandra 클러스터에 연결하기 위한 유효한 사용자 이름을 입력합니다.
암호
사용자 이름과 연결된 암호를 입력합니다.
-
확인을 선택합니다. AWS SCT가 연결을 테스트하여 Cassandra 클러스터에 액세스할 수 있는지 확인합니다.
-
메뉴 모음에서 Amazon DynamoDB에 연결을 선택합니다.

다음 정보를 입력합니다.
파라미터... 수행할 작업 AWS 프로파일에서 복사
AWS 자격 증명을 이미 설정했으면 기존 프로파일의 이름을 선택합니다.
AWS 액세스 키
AWS 액세스 키를 입력합니다. AWS 보안 키
AWS 액세스 키와 연결된 보안 키를 입력합니다. 리전
AWS 리전을 선택합니다. AWS SCT는 이 리전의 데이터를 Amazon DynamoDB로 마이그레이션합니다. -
확인을 선택합니다. AWS SCT는 연결을 테스트하여 DynamoDB에 액세스할 수 있는지 확인합니다.
복제 데이터 센터 만들기
Cassandra 클러스터를 사용하는 프로덕션 애플리케이션을 방해하지 않기 위해 AWS SCT는 복제 데이터 센터를 생성하여 프로덕션 데이터를 이 데이터 센터로 복사합니다. 복제 데이터 센터는 AWS SCT가 프로덕션 데이터 센터가 아닌 복제 데이터 센터를 사용하여 마이그레이션 활동을 수행하도록 스테이징 영역의 역할을 합니다.
복제 프로세스를 시작하려면 다음과 같이 합니다.
-
AWS SCT 창의 왼쪽(소스)에서 데이터 센터 노드를 확장하고 기존 Cassandra 데이터 센터 중 하나를 선택합니다.
-
작업 메뉴에서 Clone Datacenter for Extract(추출용 데이터 센터 복제)를 선택합니다.

-
지침을 읽은 후 다음을 선택하여 계속합니다.
-
Clone Datacenter for Extract(추출용 데이터 센터 복제) 창에 다음 정보를 추가합니다.
파라미터... 수행할 작업 프라이빗 IP:SSH 포트
Cassandra 클러스터에 있는 노드의 프라이빗 IP 주소와 SSH 포트를 입력합니다. 예: 172.28.37.102:22퍼블릭 IP:SSH 포트
노드의 퍼블릭 IP 주소와 SSH 포트를 입력합니다. 예: 41.184.48.27:22OS 사용자
노드에 연결하기 위한 유효한 사용자 이름을 입력합니다.
OS 암호
사용자 이름과 연결된 암호를 입력합니다.
키 경로 이 노드에 대한 SSH 프라이빗 키(.pem 파일)가 있으면 찾아보기를 선택하여 프라이빗 키가 저장되어 있는 위치로 이동합니다.
암호 SSH 프라이빗 키가 암호로 보호되어 있으면 안호를 여기에 입력합니다.
JMX 사용자 Cassandra 클러스터에 액세스하기 위한 JMX 사용자 이름을 입력합니다.
JMX 암호 JMX 사용자 이름과 연결된 암호를 입력합니다.
다음을 선택하여 계속합니다. AWS SCT는 Cassandra 노드에 연결하여
nodetool status명령을 실행합니다. -
Source Cluster Parameters(소스 클러스터 파라미터) 창에서 기본값을 그대로 사용하고 다음을 선택하여 계속합니다.
-
Node Parameters(노드 파라미터) 창에서 소스 클러스터의 모든 노드에 대한 연결 정보를 확인합니다. AWS SCT가 이 정보의 일부를 자동으로 입력하지만 누락된 정보는 사용자가 직접 제공해야 합니다.
참고
모든 데이터를 입력하는 대신 대량 업로드를 수행할 수 있습니다. 이렇게 하려면 내보내기를 선택하여 .csv 파일을 생성합니다. 그런 다음 이 파일을 편집하여 클러스터의 각 노드에 대해 한 행을 추가합니다. 모두 마쳤으면 업로드를 선택합니다. 그러면 AWS SCT가 .csv 파일을 읽고 그 내용을 사용하여 Node parameters(노드 파라미터) 창을 채웁니다.
다음을 선택하여 계속합니다. AWS SCT가 노드 구성이 유효한지 확인합니다.
-
Configure Target Datacenter(대상 데이터 센터 구성) 창에서 기본값을 검토합니다. 특히 Datacenter suffix(데이터 센터 접미사) 필드의 값에 주의합니다. AWS SCT는 복제 데이터 센터를 생성할 때 소스 데이터 센터와 동일하게 이름을 지정하고 이 접미사를 이름 뒤에 추가합니다. 예를 들어 소스 데이터 센터 이름이
my_datacenter인 경우 복제 데이터 센터 이름에는_tgt접미사가 추가되어my_datacenter_tgt가 됩니다. -
Configure Target Datacenter(대상 데이터 센터 구성) 창에서 Add new node(새 노드 추가)를 선택합니다.

-
Add New Node(새 노드 추가) 창에서, 복제 데이터센터를 위한 Amazon EC2 인스턴스에서 생성한 Amazon EC2 인스턴스에 연결하는 데 필요한 정보를 추가합니다.
원하는 대로 설정되었으면 추가를 선택합니다. 해당 노드가 목록에 나타납니다.

-
[Next]를 선택하여 계속 진행합니다. 다음과 같이 확인을 묻는 상자가 나타납니다.

확인을 선택하여 계속합니다. AWS SCT는 소스 데이터 센터를 한 번에 한 노드씩 재부팅합니다.
-
Datacenter Synchronization(데이터 센터 동기화) 창의 정보를 검토합니다. 클러스터가 Cassandra 버전 2에서 실행 중인 경우 AWS SCT는 모든 데이터를 복제 데이터 센터로 복사합니다. 클러스터가 Cassandra 버전 3에서 실행 중인 경우에는 복제 데이터 센터로 복사할 키스페이스를 선택할 수 있습니다.
-
복제 데이터 센터로 데이터를 복제할 준비가 끝났으면 시작을 선택합니다.
데이터 복제가 바로 시작됩니다. AWS SCT는 진행 표시줄을 표시하므로 복제 프로세스를 모니터링할 수 있습니다. 복제 작업은 소스 데이터 센터의 데이터 양에 따라 시간이 오래 걸릴 수 있습니다. 작업이 완료되기 전에 취소해야 할 경우 취소를 선택합니다.
복제가 완료되면 다음을 선택하여 계속합니다.
-
AWS SCT는 요약 창에 Cassandra 클러스터의 상태와 해당 단계를 보여 주는 보고서를 표시합니다.
이 보고서의 정보를 검토한 후 마침을 선택하여 마법사를 완료합니다.
데이터 추출 에이전트 설치, 구성 및 실행
이제 복제 데이터 센터가 생성되었으며 Cassandra용 AWS SCT 데이터 추출 에이전트를 사용할 수 있습니다. 이 에이전트는 AWS SCT 배포의 일부로 제공됩니다(자세한 내용은 AWS Schema Conversion Tool 설치, 확인 및 업데이트 참조).
참고
이 에이전트를 Amazon EC2 인스턴스에서 실행할 것을 권장합니다. EC2 인스턴스는 다음 요구 사항을 충족해야 합니다.
-
운영 체제: Ubuntu 또는 CentOS
-
가상 CPU 최소 8개
-
RAM 크기 최소 16GB.
이러한 요구 사항을 충족하는 Amazon EC2 인스턴스가 없다면, 먼저 Amazon EC2 Management Console(https://console.aws.amazon.com/ec2/)로 가서 새 인스턴스를 시작하십시오.
다음 절차에 따라 Cassandra용 AWS SCT 데이터 추출 에이전트를 설치 및 구성하고 실행합니다.
-
Amazon EC2 인스턴스에 로그인합니다.
-
Java 1.8.x가 설치되어 실행 중인지 확인합니다.
java -version -
sshfs패키지를 설치합니다.sudo yum install sshfs -
expect패키지를 설치합니다.sudo yum install expect -
/etc/fuse.conf파일을 편집하여user_allow_other줄을 주석 처리합니다.# mount_max = 1000 user_allow_other -
Cassandra용 AWS SCT 데이터 추출 에이전트는 AWS SCT 배포의 일부로 제공됩니다(자세한 내용은 AWS Schema Conversion Tool 설치, 확인 및 업데이트 참조). AWS SCT 설치 파일이 들어 있는 .zip 파일에서
agents디렉터리에 에이전트가 있습니다. 다음 빌드 버전의 에이전트를 사용할 수 있습니다.파일 이름 운영 체제 aws-cassandra-extractor-n.n.n.debUbuntu
aws-cassandra-extractor-n.n.n.x86_64.rpmCentOS
해당 Amazon EC2 인스턴스에 적합한 파일을 선택합니다.
scp유틸리티를 사용하여 이 파일을 Amazon EC2 인스턴스에 업로드합니다. -
Cassandra용 AWS SCT 데이터 추출 에이전트를 설치합니다. (
n.n.n-
Ubuntu:
sudo dpkg -i aws-cassandra-extractor-n.n.n.deb -
CentOS:
sudo yum install aws-cassandra-extractor-n.n.n.x86_64.rpm
설치 중에, 앞으로 사용할 Cassandra 버전을 선택하라는 메시지가 표시됩니다. 버전 3 또는 2를 적절히 선택합니다.
-
-
설치가 완료되면 다음 디렉터리가 생성되었는지 확인합니다.
-
/var/log/cassandra-data-extractor/— - 추출 에이전트 로그용 -
/mnt/cassandra-data-extractor/— - 마운트 홈 및 데이터 폴더용 -
/etc/cassandra-data-extractor/— - 에이전트 구성 파일용(agent-settings.yaml).
-
-
에이전트가 AWS SCT와 통신하려면 키 스토어가 있고 신뢰할 수 있는 스토어를 사용할 수 있어야 합니다. (이것은 보안 설정에서 생성했습니다.)
scp유틸리티를 사용하여 이들 파일을 Amazon EC2 인스턴스에 업로드합니다.구성 유틸리티(다음 단계 참조)를 사용하려면 키 스토어와 신뢰할 수 있는 스토어가 필요하므로 이를 제공해야 합니다.
-
구성 유틸리티를 실행합니다.
sudo java -jar /usr/share/aws-cassandra-extractor/aws-cassandra-extractor.jar --configure유틸리티에서 몇 가지 구성 값을 묻는 메시지를 표시합니다. 다음 예제를 지침으로 사용하여 원하는 값을 지정합니다.
Enter the number of data providers nodes [1]: 1 Enter IP for Cassandra node 1: 34.220.73.140 Enter SSH port for Cassandra node <34.220.73.140> [22]: 22 Enter SSH login for Cassandra node <34.220.73.140> : centos Enter SSH password for Cassandra node <34.220.73.140> (optional): Is the connection to the node using a SSH private key? Y/N [N] : Y Enter the path to the private SSH key for Cassandra node <34.220.73.140>: /home/centos/my-ec2-private-key.pem Enter passphrase for SSH private key for Cassandra node <34.220.73.140> (optional): Enter the path to the cassandra.yaml file location on the node <34.220.73.140>: /etc/cassandra/conf/ Enter the path to the Cassandra data directories on the node <34.220.73.140>: /u01/cassandra/data ===== Mounting process started ===== Node [34.220.73.140] mounting started. Will be executed command: sudo sshfs ubuntu@34.220.73.140:/etc/cassandra/ /mnt/aws-cassandra-data-extractor/34.220.73.140_node/conf/ -p 22 -o allow_other -o StrictHostKeyChecking=no -o IdentityFile=/home/ubuntu/dbbest-ec2-oregon_s.pem > /var/log/aws-cassandra-data-extractor/dmt-cassandra-v3/conf_34.220.73.140.log 2>&1 Will be executed command: sudo sshfs ubuntu@34.220.73.140:/u01/cassandra/data/ /mnt/aws-cassandra-data-extractor/34.220.73.140_node/data/data -p 22 -o allow_other -o StrictHostKeyChecking=no -o IdentityFile=/home/ubuntu/dbbest-ec2-oregon_s.pem > /var/log/aws-cassandra-data-extractor/dmt-cassandra-v3/data_34.220.73.140.log 2>&1 ===== Mounting process was over ===== Enable SSL communication Y/N [N] : Y Path to key store: /home/centos/Cassandra_key Key store password:123456 Re-enter the key store password:123456 Path to trust store: /home/centos/Cassandra_trust Trust store password:123456 Re-enter the trust store password:123456 Enter the path to the output local folder: /home/centos/out_data === Configuration aws-agent-settings.yaml successful completed === If you want to add new nodes or change it parameters, you should edit the configuration file /etc/aws-cassandra-data-extractor/dmt-cassandra-v3/aws-agent-settings.yaml참고
구성 유틸리티가 완료되면, 다음과 같은 메시지가 나타납니다.
Change the SSH private keys permission to 600 to secure them. You can also set permissions to 400.이 예제에서와 같이,
chmod명령을 사용하여 권한을 변경할 수 있습니다.chmod 400 /home/centos/my-ec2-private-key.pem -
구성 유틸리티가 완료되면 다음 디렉터리와 파일을 확인합니다.
-
/etc/cassandra-data-extractor/agent-settings.yaml— - 에이전트 설정 파일 -
$HOME/out_data— - 추출 출력 파일용 디렉터리 -
/mnt/cassandra-data-extractor/34.220.73.140_node/conf—- 비어 있는 Cassandra 홈 폴더 (34.220.73.140을 실제 IP 주소로 바꿉니다.) -
/mnt/cassandra-data-extractor/34.220.73.140_node/data/data— - 비어 있는 Cassandra 데이터 파일 (34.220.73.140을 실제 IP 주소로 바꿉니다.)
이러한 디렉터리가 탑재되지 않은 경우 다음 명령을 사용하여 탑재합니다.
sudo java -jar /usr/share/aws-cassandra-extractor/aws-cassandra-extractor.jar -mnt -
-
Cassandra 홈 및 데이터 디렉터리를 탑재합니다.
sudo java -jusr/share/cassandra-extractor/rest-extraction-service.jar -mnt탑재 프로세스가 완료되면 다음 예제에서와 같이 Cassandra 홈 폴더와 Cassandra 데이터 파일 디렉터리를 확인합니다. (
34.220.73.140을 실제 IP 주소로 바꿉니다.)ls -l /mnt/cassandra-data-extractor/34.220.73.140_node/conf ls -l /mnt/cassandra-data-extractor/34.220.73.140_node/data/data -
Cassandra용 AWS SCT 데이터 추출 에이전트를 시작합니다.
sudo systemctl start aws-cassandra-extractor참고
기본적으로 에이전트는 포트 8080에서 실행됩니다. 포트를 변경하려면
agent-settings.yaml파일을 편집합니다.
복제 데이터 센터에서 Amazon DynamoDB로 데이터 마이그레이션
이제 AWS SCT를 사용하여 복제 데이터 센터에서 Amazon DynamoDB로 마이그레이션을 수행할 수 있습니다. AWS SCT는 Cassandra용 AWS SCT 데이터 추출 에이전트, AWS Database Migration Service(AWS DMS), DynamoDB에 대한 워크플로를 관리합니다. AWS SCT 인터페이스 내에서 마이그레이션 프로세스 전체를 수행할 수 있으며, 모든 외부 구성 요소는 AWS SCT가 관리해 줍니다.
데이터를 마이그레이션하려면 다음 절차를 따릅니다.
-
보기 메뉴에서 Data migration view(데이터 마이그레이션 보기)를 선택합니다.
-
에이전트 탭을 선택합니다.
-
AWS SCT 데이터 추출 에이전트를 아직 등록하지 않은 경우 다음 메시지가 표시됩니다.

[Register]를 선택합니다.
-
New agent registration(새 에이전트 등록) 창에서 다음 정보를 추가합니다.
파라미터... 수행할 작업 설명
이 에이전트에 대한 간단한 설명을 입력합니다. Host name
데이터 추출 에이전트 설치, 구성 및 실행에 사용한 Amazon EC2 인스턴스의 호스트 이름을 입력합니다. 포트
에이전트의 포트 번호를 입력합니다. (기본 포트 번호는 8080입니다.)암호
SSL을 사용하는 경우 이 필드를 비워 두고, 그렇지 않은 경우에는 호스트 로그인 암호를 입력합니다. Use SSL
SSL을 사용하는 경우에는 이 옵션을 선택하여 SSL 탭을 활성화합니다. SSL을 사용하는 경우, SSL 탭을 선택하여 다음 정보를 추가합니다.
파라미터... 수행할 작업 신뢰할 수 있는 스토어
데이터 추출 에이전트 설치, 구성 및 실행에서 구성한 신뢰할 수 있는 스토어를 선택합니다. 키 스토어
데이터 추출 에이전트 설치, 구성 및 실행에서 구성한 키 스토어를 선택합니다. 모든 설정을 원하는 대로 지정했으면 Register(등록)를 선택합니다. 그러면 AWS SCT가 Cassandra용 AWS SCT 데이터 추출 에이전트와 연결합니다.
-
AWS SCT 창의 왼쪽에서, 복제 데이터 센터 만들기에서 만들었던 Cassandra 데이터 센터를 선택합니다.
-
작업 메뉴에서 Create Local & DMS Task(로컬 및 DMS 작업 생성)를 선택합니다.
-
Create Local & DMS Task(로컬 및 DMS 작업 생성) 창에서 다음 정보를 입력합니다.
파라미터... 수행할 작업 [Task name]
생성할 AWS DMS 작업의 짧은 이름을 입력합니다. 복제 인스턴스
사용할 AWS DMS 복제 인스턴스를 선택합니다. [Migration type]
Migrate existing data and replication ongoing changes(기존 데이터와 복제 진행 중 변경 사항 마이그레이션)를 선택합니다. 그러면 Cassandra 복제 데이터 센터의 테이블이 DynamoDB로 마이그레이션된 후 진행 중인 모든 변경 사항이 캡처됩니다. 이 프로세스를 AWS DMS에서는 전체 로드 및 CDC라고 합니다. [Target table preparation mode]
DynamoDB에 해당 테이블이 이미 있고 마이그레이션하기 전에 이를 삭제하려면, Drop tables on target(대상의 테이블 삭제)을 선택합니다. 그 외의 경우에는 이 설정을 기본값으로 유지합니다(아무 작업 안 함). IAM 역할
Amazon S3 버킷과 대상 데이터베이스(Amazon DynamoDB)에 액세스할 수 있는 권한을 가진, 미리 정의된 IAM 역할을 선택합니다. Amazon S3 버킷에 액세스하는 데 필요한 권한에 대한 자세한 내용은 섹션을 참조하십시오. 로깅 수준
마이그레이션 작업에 적합한 로깅 옵션을 선택합니다. 설명
작업 설명을 입력합니다. 데이터 암호화
Enable(사용) 또는 Disable(사용 안 함)을 선택합니다. 로컬 디렉터리에서 파일 삭제
데이터 파일을 Amazon S3에 로드한 후 에이전트의 로컬 디렉터리에서 데이터 파일을 삭제하려면 이 옵션을 선택합니다. S3 버킷
사용자가 쓰기 권한을 가진 Amazon S3 버킷의 이름을 입력합니다. 원하는 대로 설정되었으면 [Create]를 선택합니다.
-
작업 탭을 선택합니다. 생성한 작업이 이 탭에 표시됩니다. 작업을 시작하려면 시작을 선택합니다.
다음 스크린샷에서 볼 수 있듯이, 작업 진행 상황을 모니터링할 수 있습니다.

마이그레이션 후 작업
마이그레이션을 마친 후 마이그레이션 작업을 삭제하려면 다음과 같이 합니다.
-
[Tasks] 탭을 선택합니다.
-
작업이 현재 실행 중인 경우 중지를 선택합니다.
-
작업을 삭제하려면 삭제를 선택합니다.
Cassandra용 AWS SCT 데이터 추출 에이전트가 더 이상 필요하지 않으면 다음과 같이 합니다.
-
에이전트 탭을 선택합니다.
-
더 이상 필요 없는 에이전트를 선택합니다.
-
등록 취소를 선택합니다.
'11. AWS' 카테고리의 다른 글
| 애플리케이션 SQL 변환 (0) | 2018.12.21 |
|---|---|
| AWS Schema Conversion Tool을 사용하여 애플리케이션 SQL 변환 (0) | 2018.12.21 |
| Amazon Redshift을 사용하여 AWS Schema Conversion Tool 최적화 (0) | 2018.12.21 |
| Amazon Redshift 관리 개요 (0) | 2018.12.21 |
| Amazon Redshift란 무엇입니까? (0) | 2018.12.21 |
- Total
- Today
- Yesterday
- 테라폼
- 커널
- 오라클
- directory copy 후 startup 에러
- pod 상태
- 오라클 인스턴트클라이언트(InstantClient) 설치하기(HP-UX)
- (InstantClient) 설치하기(HP-UX)
- 튜닝
- ubuntu
- MSA
- 우분투
- [오라클 튜닝] sql 튜닝
- Oracle
- K8s
- 5.4.0.1072
- 키알리
- 오라클 홈디렉토리 copy 후 startup 에러
- CVE 취약점 점검
- 버쳐박스
- 코로나19
- 오라클 트러블 슈팅(성능 고도화 원리와 해법!)
- startup 에러
- 트리이스
- ORACLE 트러블 슈팅(성능 고도화 원리와 해법!)
- 여러서버 컨트롤
- [오라클 튜닝] instance 튜닝2
- 앤시블
- 스토리지 클레스
- 쿠버네티스
- 설치하기(HP-UX)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |