
티스토리 뷰
참고 원본 : https://docs.ray.io/en/latest/ray-overview/index.html
Overview — Ray 2.24.0
Stack of Ray libraries - unified toolkit for ML workloads.
docs.ray.io
레이 프레임워크

Ray의 통합 컴퓨팅 프레임워크는 세 가지 계층으로 구성됩니다.
- Ray AI Libraries – ML 엔지니어, 데이터 과학자 및 연구원에게 ML 애플리케이션을 위한 확장 가능하고 통합된 툴킷을 제공하는 오픈 소스, Python, 도메인별 라이브러리 세트입니다.
- Ray Core – ML 엔지니어와 Python 개발자가 Python 애플리케이션을 확장하고 기계 학습 워크로드를
가속화할 수 있도록 지원하는 오픈 소스 Python 범용 분산 컴퓨팅 라이브러리입니다. - Ray Cluster – 공통 Ray 헤드 노드에 연결된 작업자 노드 세트입니다. Ray 클러스터는 고정 크기이거나 클러스터에서 실행되는 애플리케이션이 요청한 리소스에 따라 자동으로 확장 및 축소될 수 있습니다.
Ray의 5개 기본 라이브러리는 각각 특정 ML 작업을 배포합니다.
- 데이터 : 훈련, 튜닝, 예측 전반에 걸쳐 확장 가능하고 프레임워크에 구애받지 않는 데이터 로드 및 변환.
- 훈련 : 널리 사용되는 훈련 라이브러리와 통합되는 내결함성을 갖춘 분산 다중 노드 및 다중 코어 모델 훈련입니다.
- 조정 : 모델 성능을 최적화하기 위한 확장 가능한 하이퍼파라미터 조정입니다.
- Serve : 성능 향상을 위한 선택적 마이크로배칭을 통해 온라인 추론을 위한 모델을 배포하기 위한 확장 가능하고
프로그래밍 가능한 서비스입니다.
- RLlib : 확장 가능한 분산 강화 학습 워크로드입니다.
Ray의 라이브러리는 데이터 과학자와 ML 엔지니어 모두를 위한 것입니다. 데이터 과학자의 경우 이러한 라이브러리를 사용하여 개별 워크로드와 엔드투엔드 ML 애플리케이션을 확장할 수 있습니다. ML 엔지니어를 위해 이러한 라이브러리는 더 광범위한 ML 생태계의 도구를 쉽게 온보딩하고 통합하는 데 사용할 수 있는 확장 가능한 플랫폼 추상화를 제공합니다.
맞춤형 애플리케이션의 경우 Ray Core 라이브러리를 통해 Python 개발자는 노트북, 클러스터, 클라우드 또는 Kubernetes에서 실행할 수 있는 확장 가능한 분산 시스템을 쉽게 구축할 수 있습니다. 이는 Ray AI 라이브러리 및 타사 통합(Ray 생태계)이 구축되는 기반입니다.
Ray는 모든 시스템, 클러스터, 클라우드 제공업체 및 Kubernetes에서 실행되며 성장하는 커뮤니티 통합 생태계를 제공합니다 .
KubeRay core:
RayCluster, RayJob, RayService 라는 세 가지 사용자 정의 리소스 정의를 제공하는 KubeRay의 공식적이고 완벽하게 유지 관리되는 구성 요소입니다. 이러한 리소스는 다양한 워크로드를 쉽게 실행할 수 있도록 설계되었습니다.
- RayCluster: KubeRay는 클러스터 생성/삭제, 자동 확장, 내결함성 보장 등 RayCluster의 수명 주기를 완벽하게 관리합니다.
- RayJob: 레이잡을 사용하면 KubeRay는 자동으로 레이클러스터를 생성하고 클러스터가 준비되면 작업을 제출합니다. 또한 작업이 완료되면 자동으로 RayCluster를 삭제하도록 RayJob을 구성할 수도 있습니다.
- RayService: 레이서비스는 레이클러스터와 레이서브 배포 그래프의 두 부분으로 구성됩니다. 레이서비스는 레이클러스터의 다운타임 제로 업그레이드와 고가용성을 제공합니다.
🧿 주요 기능
- Ray 클러스터 관리
- KubeRay는 Kubernetes에서 Ray 클러스터의 생성을 자동화합니다. 사용자는 YAML 파일을 사용하여 Ray 클러스터를 정의하고, KubeRay는 이를 기반으로 클러스터를 생성합니다.
- 자동 확장
- KubeRay는 클러스터의 자원 사용량을 모니터링하고 필요에 따라 클러스터의 크기를 자동으로 조정할 수 있습니다. 이는 작업 부하에 따라 클러스터 노드 수를 동적으로 증가시키거나 감소시킴으로써 자원 효율성을 극대화합니다.
- 간편한 배포
- KubeRay를 사용하면 Kubernetes 환경에서 Ray 애플리케이션을 쉽게 배포할 수 있습니다. Kubernetes의 네이티브 도구와 통합되어, 기존 Kubernetes 사용자에게 친숙한 환경을 제공합니다.
- 모니터링 및 로깅
- KubeRay는 Prometheus 및 Grafana와 같은 모니터링 도구와 통합하여 Ray 클러스터의 상태를 실시간으로 모니터링할 수 있습니다. 또한, 로그를 중앙에서 관리하여 디버깅을 용이하게 합니다.
🧿 KubeRay의 구성 요소
- KubeRay Operator
- KubeRay Operator는 Kubernetes 컨트롤러로서, Ray 클러스터의 상태를 관리하고 업데이트합니다. 사용자가 정의한 YAML 파일을 읽고, 이에 따라 Kubernetes 리소스를 생성하고 관리합니다.
- RayCluster Custom Resource
- RayCluster Custom Resource는 Ray 클러스터를 정의하는 Kubernetes 리소스입니다. 사용자는 이 리소스를 통해 클러스터의 구성, 예를 들어 헤드 노드와 워커 노드의 수, 리소스 할당 등을 설정할 수 있습니다.
- Ray Dashboard
- KubeRay는 Ray Dashboard에 접근할 수 있는 기능을 제공합니다. Ray Dashboard는 클러스터의 상태와 작업의 진행 상황을 시각적으로 보여주는 웹 인터페이스입니다.
✅ Ray
- 확장 가능하고 유연한 분산 컴퓨팅 프레임워크로, 특히 대규모 병렬 작업을 효율적으로 처리하는 데 사용
- 머신 러닝 및 데이터 처리와 같은 고성능 컴퓨팅 애플리케이션을 쉽게 개발하고 실행할 수 있도록 설계되었습니다.
🧿 주요 기능
- 단순한 API
- Ray는 간단하고 직관적인 API를 제공하여 사용자가 분산 컴퓨팅 작업을 쉽게 작성할 수 있도록 돕습니다. Python 코드를 기반으로 하며, 간단한 데코레이터를 사용해 함수나 클래스를 분산 작업으로 변환할 수 있습니다.
- 자동 병렬화
- Ray는 함수 호출을 자동으로 병렬화하고 클러스터의 여러 노드에 작업을 분산시킵니다. 이를 통해 사용자는 별도의 병렬 처리 코드를 작성하지 않고도 성능을 극대화할 수 있습니다.
- 내장 스케줄러
- Ray의 내장 스케줄러는 작업을 자동으로 스케줄링하고, 클러스터의 자원을 최적으로 사용할 수 있도록 합니다. 이를 통해 작업 부하가 동적으로 변하는 환경에서도 안정적인 성능을 보장합니다.
- 유연한 분산 데이터 처리
- Ray는 대규모 데이터셋을 다루는 작업을 지원하며, 분산 데이터 프레임인 Ray Datasets를 제공하여 효율적인 데이터 처리를 가능하게 합니다.
- 확장성
- Ray는 수천 개의 노드를 가진 클러스터에서도 동작할 수 있으며, 작업 부하에 따라 유연하게 확장 및 축소할 수 있습니다. 이는 특히 클라우드 환경에서 유리합니다.
🧿 주요 구성 요소

- Ray Core
- Ray의 핵심 라이브러리로, 분산 작업을 정의하고 실행하는 데 필요한 기본 API를 제공합니다. 원격 함수(remote function)와 액터(actor)를 사용하여 병렬 작업을 관리합니다.
- Ray Datasets
- 대규모 데이터셋을 처리하기 위한 고성능 분산 데이터 프레임입니다. Pandas와 유사한 API를 제공하며, 분산 환경에서 데이터를 효율적으로 처리할 수 있습니다.
- Ray Tune
- 하이퍼파라미터 튜닝 라이브러리로, 머신 러닝 모델의 성능을 최적화하는 데 사용됩니다. 다양한 최적화 알고리즘을 제공하며, 분산 환경에서 빠르게 튜닝 작업을 수행할 수 있습니다.
- Ray Serve
- 머신 러닝 모델을 배포하고 관리하기 위한 고성능 모델 서비스 라이브러리입니다. 쉽게 확장 가능하며, 여러 모델을 동시에 서비스할 수 있습니다.
- Ray RLlib
- 강화 학습 라이브러리로, 다양한 강화 학습 알고리즘을 제공하여 복잡한 강화 학습 문제를 해결할 수 있습니다. 대규모 분산 학습을 지원합니다.
https://ray-project.github.io/kuberay/deploy/helm/
Helm - KubeRay Docs
KubeRay Operator This document provides instructions to install both CRDs (RayCluster, RayJob, RayService) and KubeRay operator with a Helm chart. Helm Make sure the version of Helm is v3+. Currently, existing CI tests are based on Helm v3.4.1 and v3.9.4.
ray-project.github.io
✅ KubeRay operator 배포하기
헬름 차트 리포지토리로 KubeRay 오퍼레이터를 배포합니다.
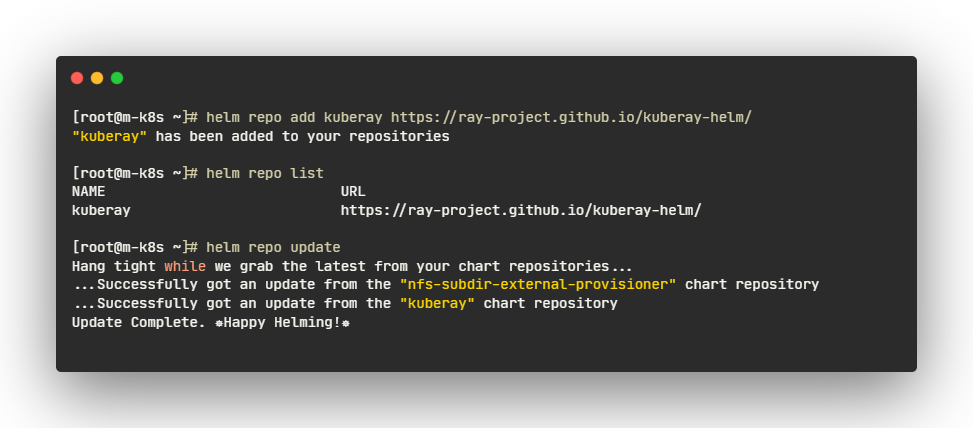
- CRD와 KubeRay 오퍼레이터 v1.1.1을 설치합니다.
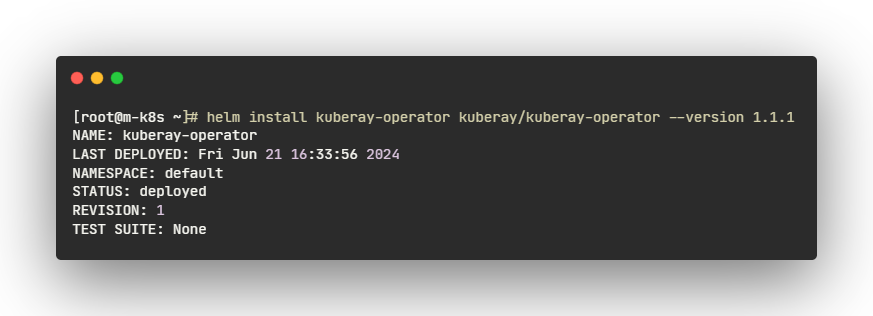
- operator 가 네임스페이스 'default'에서 실행 중인지 확인합니다.

✅ RayCluster 사용자 정의 리소스 배포
KubeRay 오퍼레이터가 실행되면 RayCluster를 배포할 준비가 된 것입니다. 이를 위해 기본 네임스페이스에 RayCluster 커스텀 리소스(CR)를 생성합니다.
- KubeRay Helm 차트 리포지토리에서 샘플 RayCluster CR을 배포합니다

- RayCluster CR 생성울 확인합니다.

- KubeRay 오퍼레이터가 RayCluster 객체를 감지합니다. 그러면 operator 는 head 와 worker 파드를 생성하여 RayCluster 를 시작합니다. RayCluster 의 파드를 확인합니다.
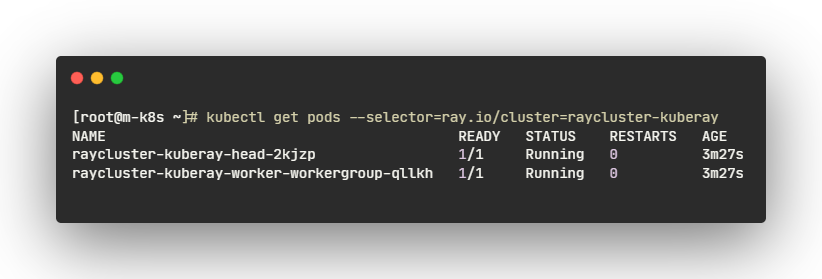
- 파드가 실행 중 상태가 될 때까지 기다립니다. 이 시간은 대부분 레이 이미지를 다운로드하는 데 소요되므로 몇 분 정도 걸릴 수 있습니다. 파드가 보류(Pending) 상태에 있는 경우, kubectl 설명 파드 raycluster-kuberay-xxxx-xxxxx를 통해 오류를 확인하고 Docker 리소스 제한이 충분히 높게 설정되어 있는지 확인할 수 있습니다. 프로덕션 시나리오에서는 더 큰 레이 파드를 사용하는 것이 좋습니다. 실제로 각 레이 파드의 크기를 전체 Kubernetes 노드를 차지하도록 설정하는 것이 유리합니다.
✅ RayCluster 에서 애플리케이션 실행
🧿 head Pod 에서 Ray job 실행하기
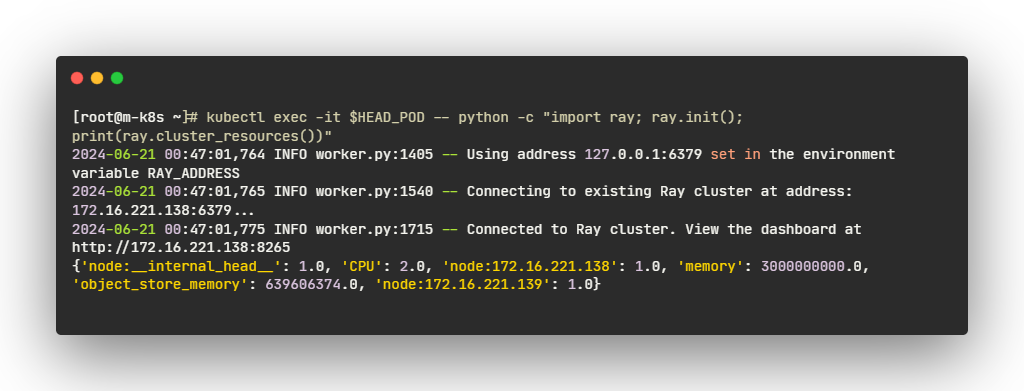
- RayCluster 를 실험하는 가장 간단한 방법은 head pod 에서 직접 실행하는 것입니다. 먼저, RayCluster 의 head pod 를 식별합니다:

- 클러스터 리소스를 확인합니다.
✅ Ray Dashboard 액세스
- 대시보드를 보려면 브라우저에서 ${YOUR_IP}:8265로 이동합니다. 예를 들어 127.0.0.1:8265입니다. 아래 그림과 같이 최근 작업 창에서 4단계에서 제출한 작업을 확인합니다.

- Total
- Today
- Yesterday
- 코로나19
- 커널
- 오라클 인스턴트클라이언트(InstantClient) 설치하기(HP-UX)
- [오라클 튜닝] instance 튜닝2
- directory copy 후 startup 에러
- 쿠버네티스
- Oracle
- 테라폼
- 스토리지 클레스
- ubuntu
- 오라클 홈디렉토리 copy 후 startup 에러
- 오라클
- 트리이스
- startup 에러
- pod 상태
- 우분투
- CVE 취약점 점검
- 설치하기(HP-UX)
- 버쳐박스
- K8s
- 여러서버 컨트롤
- (InstantClient) 설치하기(HP-UX)
- 오라클 트러블 슈팅(성능 고도화 원리와 해법!)
- 앤시블
- MSA
- [오라클 튜닝] sql 튜닝
- 튜닝
- 키알리
- 5.4.0.1072
- ORACLE 트러블 슈팅(성능 고도화 원리와 해법!)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |